
Чи впливає schema.org на AI-видимість? Структуровані дані для AI не є окремим фактором, який змушує ChatGPT, Google AI Overviews або Copilot згадувати бренд. Вони допомагають пошуковим системам точніше зрозуміти сторінку, зіставити факти із сутностями та показати підтримувані розширені результати.
Нижче розберемо, де schema markup корисна для AI SEO, які типи schema варто використовувати, як перевірити розмітку і чому Google не вимагає спеціальної мікророзмітки для AI Overviews. Базову рамку дає матеріал що таке AI-видимість і чому бізнесу вже недостатньо SEO.
Що таке структуровані дані
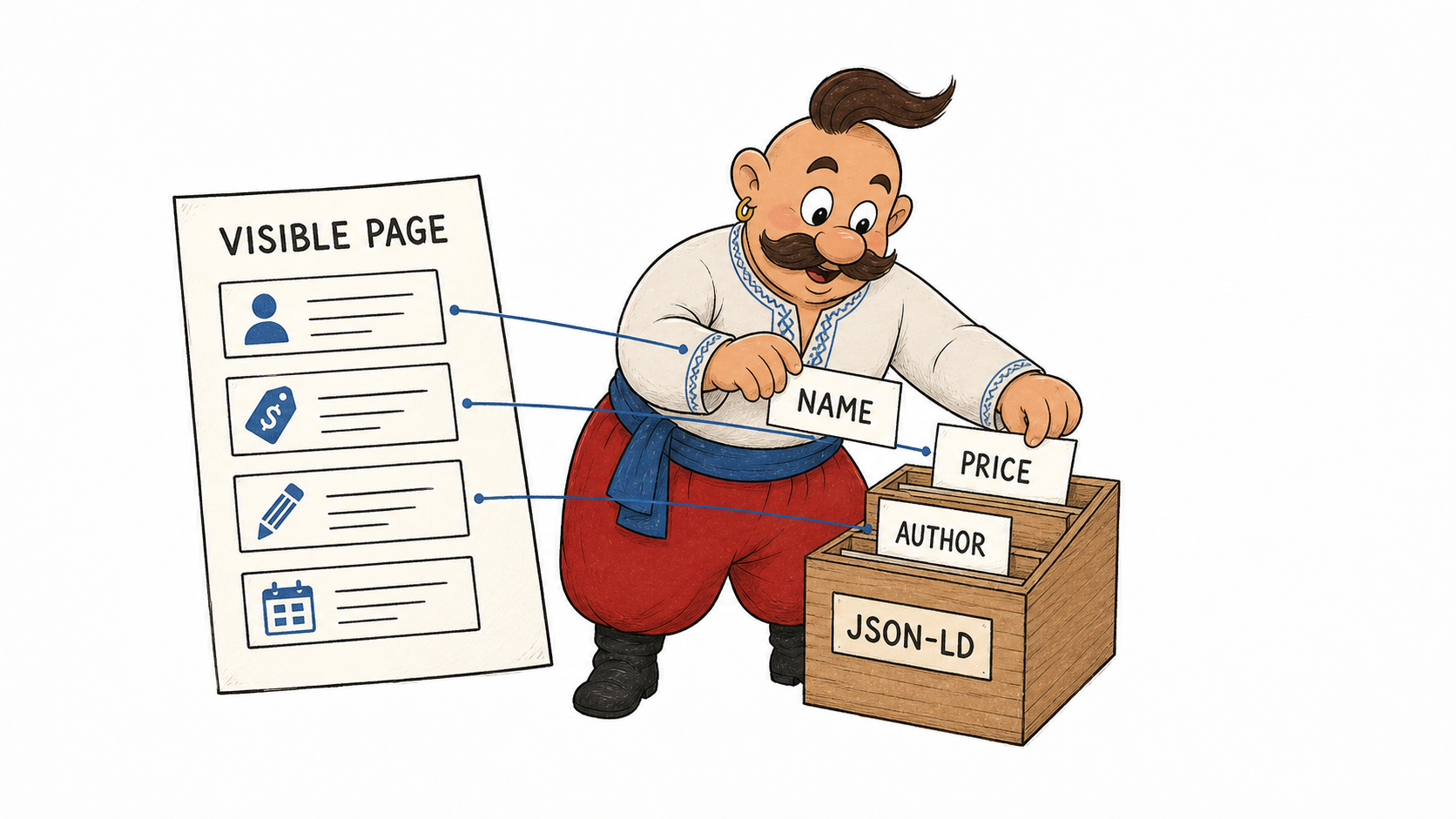
Структуровані дані — це стандартизований спосіб описати зміст сторінки у машинно-читабельному форматі. Для людини сторінка може виглядати як звичайний текст: назва компанії, ціна товару, рейтинг, адреса, автор статті. Для пошукової системи ті самі факти можна додатково описати через JSON-LD, Microdata або RDFa.
На практиці найчастіше використовують JSON-LD: окремий блок коду в HTML, який не змінює видимий текст, але пояснює, що саме є компанією, продуктом, автором, відгуком, подією чи статтею.
Основний словник — Schema.org. Це набір типів і властивостей для опису сутностей: Organization, Person, Product, Article, LocalBusiness, Event, Review, AggregateRating та багатьох інших. Schema.org ширший за можливості окремої пошукової системи. Те, що тип існує у словнику, не означає, що Google, Bing або AI-інтерфейс покажуть спеціальний блок у видачі.
Google пояснює structured data як формат, що дає явні підказки про значення сторінки та допомагає класифікувати її контент (Google Search Central). Це точне формулювання: підказки, а не команда алгоритму.
Як structured data працює у пошуку
Пошукові системи використовують структуровані дані у двох великих сценаріях.
Перший — розуміння сторінки. Коли сторінка містить Article, Organization, Product або BreadcrumbList, пошуковій системі легше зв'язати текст із конкретними сутностями: хто автор, що продається, яка ціна, де розташований бізнес, як сторінка вписана в ієрархію сайту.
Другий — search features, тобто розширені елементи у видачі. Google прямо пише, що structured data може зробити сторінку придатною для rich results: наприклад, товар може показувати ціну й наявність, рецепт — час приготування, подія — дату. Слово "може" тут ключове. Навіть валідна розмітка не гарантує показу.
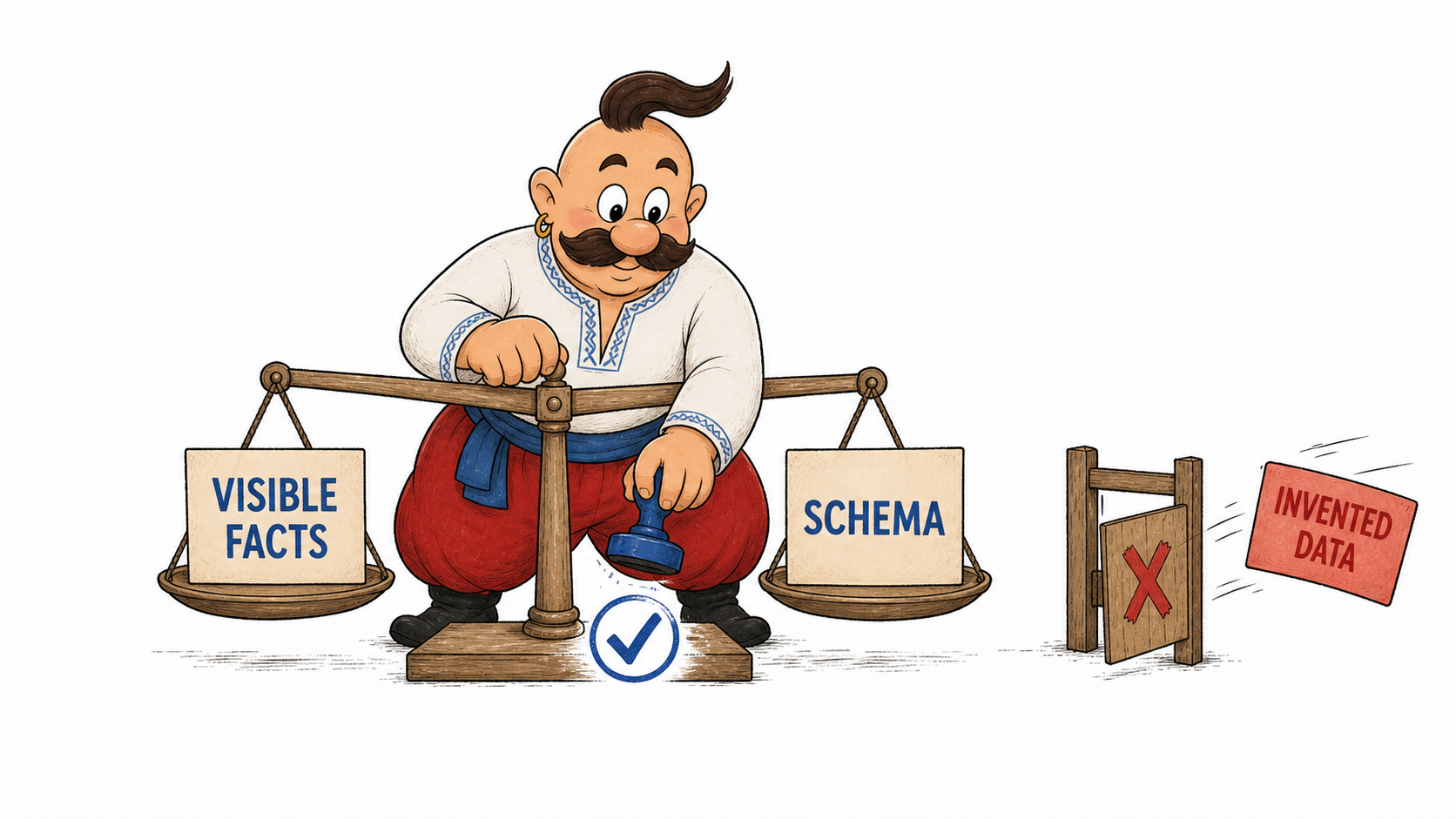
Є ще одна умова, яку не можна ігнорувати: structured data має відповідати видимому контенту сторінки. У загальних правилах Google для структурованих даних прямо сказано, що розмітка має правдиво представляти контент сторінки. Bing формулює ту саму вимогу у своїх Webmaster Guidelines: markup має точно відображати видимий контент.
Тому правильна логіка така:
| Що є на сторінці | Що можна розмічати | Що не можна робити |
|---|---|---|
| Стаття з автором і датою | Article, author, datePublished, publisher | Вказувати автора, якого немає на сторінці |
| Картка товару з ціною | Product, Offer, price, availability | Додавати рейтинг без реальних відгуків |
| Локальна сторінка філії | LocalBusiness, адреса, телефон, години роботи | Розмічати місто, де бізнес не працює |
| Сторінка з питаннями й відповідями | FAQPage, якщо Q&A реально видимі | Ховати FAQ у JSON-LD без блоку на сторінці |
Де тут AI-видимість
AI-видимість — це не тільки класичний рейтинг у Google. Це присутність бренду, сторінки або продукту у відповідях AI-систем: Google AI Overviews і AI Mode, ChatGPT Search, Bing/Copilot, Perplexity, Gemini та інших інтерфейсах із вебпошуком або цитуванням.
Structured data впливає на цей шар не як окрема "AI schema", а як частина зрозумілості сторінки. Коли AI-система або пошуковий шар, на який вона спирається, читає сторінку, їй потрібні чіткі факти. Розмітка допомагає не губити ці факти у тексті.
Це особливо важливо для запитів, де користувач просить не абстрактну пораду, а конкретику:
- "які CRM мають безкоштовний тариф";
- "порадь агентство performance marketing у Києві";
- "який товар є в наявності";
- "хто автор цього дослідження";
- "де знайти офіційні умови повернення";
- "які джерела підтверджують ціну або рейтинг".
У таких сценаріях AI-відповідь часто збирається з кількох сторінок. Чим точніше сторінка описує сутності, тим менше шансів, що модель сплутає продукт із категорією, автора з брендом, стару ціну з актуальною або сторінку філії з головним офісом.
Але важливо не перебільшувати. У документації Google для AI features сказано, що для AI Overviews і AI Mode сторінка має бути проіндексована та придатна для показу зі snippet у Google Search; додаткових технічних вимог немає. Там же Google нагадує, що structured data має відповідати видимому тексту. Тобто schema корисна, але вона не є окремим пропуском у AI Overviews.
Що structured data може покращити
Найпрактичніший вплив structured data — не "підняти позицію", а зменшити неоднозначність. Для AI-видимості це вже багато.
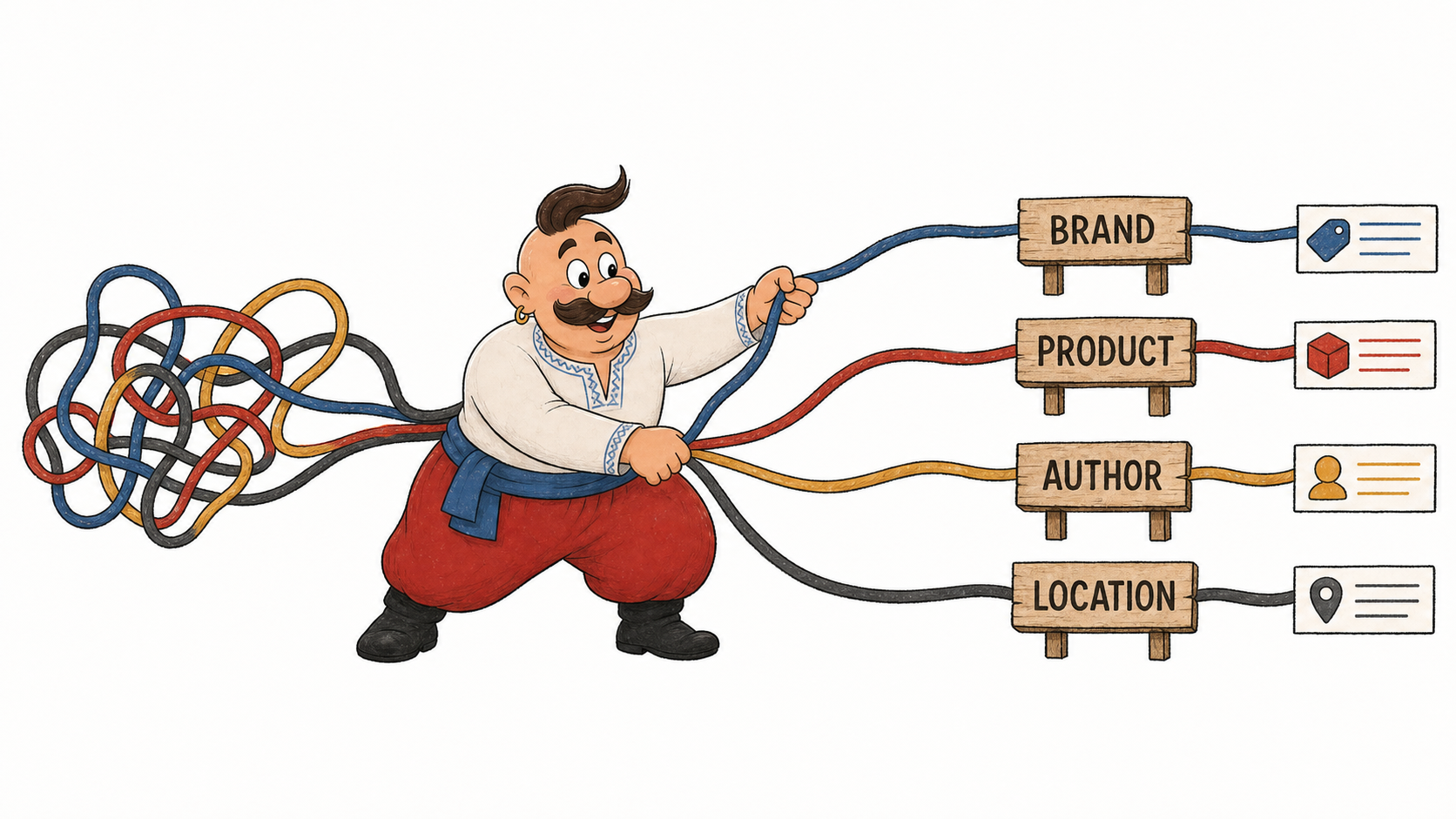
1. Розуміння сутностей
Сутність — це конкретний об'єкт, який можна впізнати: компанія, людина, товар, локація, стаття, подія. Якщо на сайті є сторінка послуги, авторська колонка і кілька продуктових сторінок, розмітка допомагає розвести ці об'єкти між собою.
Наприклад, Organization із постійним @id, логотипом, офіційною назвою та sameAs для профілів бренду допомагає пошуковим системам стабільніше пов'язувати сайт із зовнішніми згадками. Це не замінює PR і репутацію, але прибирає частину технічної плутанини.
2. Rich results і додаткові точки входу
Rich results не є AI-відповіддю, але вони впливають на видимість у пошуку. Якщо товарна сторінка показує ціну, наявність і рейтинг, користувач швидше розуміє, чи варто відкривати сайт. У e-commerce Google окремо описує Product structured data і радить поєднувати розмітку на сторінках із Merchant Center feed, щоб підвищити eligibility для торгових досвідів і допомогти Google перевіряти дані (Google Product structured data).
Це важливо для AI-пошуку, бо частина AI-відповідей спирається на ті самі або суміжні індексні дані. Якщо пошукова система краще розуміє товар, ціну й availability, AI-шару простіше використати ці факти без домислів.
3. Узгодженість між сайтом і зовнішніми джерелами
AI-системи рідко дивляться тільки на ваш сайт. Вони можуть бачити каталоги, медіа, рейтинги, профілі компанії, відгуки, маркетплейси. Якщо назва бренду, категорія, адреса, телефон, опис послуг і посилання на профілі всюди різні, модель отримує шум.
Structured data на власному сайті не виправить усі зовнішні джерела. Але вона задає канонічний опис. Далі його треба синхронізувати з Business Profile, Merchant Center, профілями у каталогах, сторінками у медіа й PR-матеріалами. Про те, як читати цей шар, окремо писали в статті як аналізувати джерела, на які спирається ШІ.
4. Машиночитаність без гарантії цитування
Щоб сторінку можна було використати як джерело, важливі факти мають бути доступні у видимому тексті: у чітких заголовках, відповідях, таблицях і актуальних описах. JSON-LD може допомогти пошуковій системі інтерпретувати сутності, але публічних доказів, що сама наявність schema підвищує частоту AI-цитування, немає.
Structured data доповнює цю архітектуру, а не замінює її. Якщо видимого тексту немає або він не відповідає розмітці, schema не робить сторінку корисним джерелом.
Чого structured data не робить
Чесна стаття про schema має проговорити обмеження.
Structured data не гарантує:
- появу в Google AI Overviews або AI Mode;
- згадку бренду в ChatGPT Search, Copilot чи Perplexity;
- вищу позицію в органічній видачі сама по собі;
- показ rich result для кожної валідної сторінки;
- виправлення проблем із
noindex, robots.txt, canonical, CDN або повільним рендерингом; - довіру до вигаданих рейтингів, фейкових авторів або неіснуючих відгуків.
Її краще сприймати як технічну інфраструктуру. Вона не створює цінність замість контенту, але допомагає машинам цю цінність побачити.
AI-краулери і доступність сторінки
Для AI-видимості важливо не лише те, що написано на сторінці, а й чи може система її прочитати.
Google для AI features використовує той самий фундамент, що й для Search: сторінка має бути доступною для crawl, індексації та snippet. OpenAI має окремий краулер OAI-SearchBot для ChatGPT search. У документації OpenAI пояснює, що OAI-SearchBot відповідає за показ сайтів у пошукових функціях ChatGPT, а GPTBot — окремий user-agent для потенційного навчання моделей. Ці правила можна налаштовувати незалежно.
OpenAI також пише у FAQ для видавців і розробників, що публічні сайти можуть з'являтися в ChatGPT search, а для summaries і snippets не треба блокувати OAI-SearchBot. Там же вказано, що переходи з ChatGPT search можна відстежувати через utm_source=chatgpt.com.
Що з цього випливає на практиці:
| Якщо хочете | Перевірте |
|---|---|
| Бути доступними для Google AI Overviews | Індексацію, snippets, robots.txt, canonical, видимий текст |
| Бути доступними для ChatGPT Search | Чи не заблокований OAI-SearchBot |
| Не дозволяти використання для навчання OpenAI | Правила для GPTBot, окремо від OAI-SearchBot |
| Міряти переходи з ChatGPT | Аналітику за utm_source=chatgpt.com |
| Зменшити хибні цитати | Актуальні сторінки, чіткі дати, canonical і структуровані факти |
Які типи schema мають найбільший сенс
Не треба розмічати все підряд. Корисна розмітка починається з питання: яка головна сутність цієї сторінки?
| Тип сторінки | Доцільні типи Schema.org | Що це дає |
|---|---|---|
| Головна або сторінка "Про нас" | Organization, WebSite | Закріплює назву бренду, сайт, логотип, соціальні профілі |
| Сторінка локальної філії | LocalBusiness, PostalAddress, OpeningHoursSpecification | Допомагає не плутати локації, адреси й телефони |
| Блогова стаття або дослідження | Article, BlogPosting, Person або Organization для автора | Пояснює авторство, дату публікації, видавця |
| Продуктова сторінка | Product, Offer, AggregateRating, Review | Передає ціну, availability, SKU/GTIN, рейтинг, відгуки |
| Категорія товарів | CollectionPage, breadcrumbs; обережно з Product | Не підміняє категорію конкретним товаром |
| FAQ-блок | FAQPage | Має сенс лише якщо питання й відповіді видимі користувачу |
| Відео або вебінар | VideoObject, Event | Допомагає описати відео, дату, тривалість, доступ |
| Дані або каталог | Dataset, ItemList, BreadcrumbList | Дає структуру наборам даних і спискам |
Для більшості бізнесів стартовий набір простий: Organization, WebSite, BreadcrumbList, Article для блогу, Product для товарів, LocalBusiness для локальних сторінок. Далі — за реальним типом контенту.
Як впроваджувати structured data без хаосу
Починайте не з плагіна, а з карти сутностей. Інакше сайт швидко отримує три різні Organization, конфліктні breadcrumbs і товарні рейтинги, які не збігаються з видимим контентом.
1. Визначте primary entity для кожного шаблону
Для сторінки товару primary entity — товар. Для статті — матеріал і автор. Для сторінки філії — локальний бізнес у конкретній локації. Для категорії — колекція або список, а не один вигаданий продукт.
2. Використовуйте стабільні @id
@id працює як постійний ідентифікатор сутності. Він допомагає зв'язувати різні блоки JSON-LD між собою.
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "Organization",
"@id": "https://example.com/#organization",
"name": "Example",
"url": "https://example.com/",
"logo": "https://example.com/logo.png"
},
{
"@type": "Article",
"@id": "https://example.com/blog/article/#article",
"headline": "Назва статті",
"publisher": {
"@id": "https://example.com/#organization"
}
}
]
}
Це не обов'язково має бути саме такий код, але принцип корисний: одна сутність — один стабільний ідентифікатор.
3. Звірте JSON-LD з видимою сторінкою
Перед релізом відкрийте сторінку як користувач і як розробник. Якщо у JSON-LD є ціна, вона має бути на сторінці. Якщо є рейтинг, мають бути реальні відгуки або коректний блок з джерелом оцінки. Якщо є автор, користувач має бачити цього автора.
4. Приберіть дублікати від плагінів
CMS-плагіни часто додають власну schema автоматично. Це зручно, доки два плагіни не починають описувати сторінку по-різному. Перевірте, чи немає дубльованих Organization, різних canonical URL, кількох Article з різними датами або конфліктних Product.
5. Пов'яжіть structured data з контентною архітектурою
Schema працює краще, коли сторінка вже добре структурована. Якщо потрібно зрозуміти, які саме сторінки варто підсилювати, подивіться матеріал які сторінки сайту найчастіше потрапляють у відповіді ШІ. Там логіка така сама: модель шукає не "SEO-текст", а сторінку, яка дає чітку відповідь.
Як перевіряти, чи є ефект
Оцінювати structured data тільки через валідатор недостатньо. Валідатор показує, чи розмітка технічно читається. Він не показує, чи зросла AI-видимість.
Базова схема перевірки:
- Технічна валідність. Перевірити сторінку у Rich Results Test, Schema.org Validator, Google Search Console і Bing Webmaster Tools.
- Відповідність сторінці. Звірити розмітку з видимим текстом, цінами, датами, авторами, breadcrumbs.
- Індексація. Переконатися, що сторінка доступна для crawl, не закрита
noindex, не заблокована robots.txt і має правильний canonical. - Поведінка у Search. Дивитися Search Console: impressions, CTR, enhancements, помилки structured data.
- AI-цитування. Перевіряти набір запитів у ChatGPT Search, Google AI Overviews, Perplexity, Copilot і фіксувати, чи з'являється сторінка як джерело.
- Логи й аналітика. Дивитися server logs для ботів і referral traffic, зокрема
utm_source=chatgpt.com.
Для AI-видимості важливо міряти не одну відповідь, а повторюваність. Один prompt може випадково не показати сторінку. Серія з 40-80 запитів уже дає картину: чи зростає частка цитувань, які URL потрапляють у відповіді, які конкуренти залишаються сильнішими. Як перетворити це в план дій, описали в матеріалі як AI visibility report перетворити на план для SEO, контенту та PR.

Типові помилки
Найчастіше проблеми виникають не через складність Schema.org, а через спробу використати schema як косметичний шар поверх слабкого контенту.
- Розмітка невидимого контенту. Наприклад, FAQ є тільки в JSON-LD, але не показаний користувачу.
- Фейкові рейтинги.
AggregateRatingбез реальних відгуків або із завищеною оцінкою, якої немає на сторінці. - Неправильний тип сторінки. Категорію розмічають як один товар, статтю — як продукт, сервісну сторінку — як локальний бізнес без локації.
- Конфлікт між CMS-плагінами. Один плагін генерує
Organization, другий — іншуOrganization, третій додає breadcrumbs з іншим URL. - Застарілі поля. Ціна, availability, дата оновлення, робочі години або адреса в JSON-LD відрізняються від реальності.
- Надмірний
sameAs. У профілі бренду додають випадкові каталоги, старі соцмережі або сторінки, які не підтверджують сутність. - Очікування гарантій. Команда впровадила schema й чекає автоматичного росту AI-згадок, хоча немає сильних сторінок, зовнішніх джерел і доступності для краулерів.
Міфи і факти
| Міф | Факт |
|---|---|
| Schema гарантує потрапляння в AI Overview | Ні. Для Google AI features потрібна індексація і snippet eligibility, але показ не гарантується |
| Існує спеціальна schema для AI-відповідей | Для Google AI Overviews і AI Mode немає окремої обов'язкової AI-розмітки |
| Чим більше типів Schema.org додати, тим краще | Корисна тільки релевантна розмітка, яка відповідає сторінці |
| Можна розмітити те, чого немає у видимому контенті | Це порушує правила Google і Bing |
| Structured data замінює контент | Ні. Вона пояснює контент, а не створює його |
| Якщо rich result не з'явився, schema марна | Ні. Вона все одно може допомагати розумінню сторінки, але без видимого спецблоку |
Коли structured data дає найбільший ефект
Найбільша користь з'являється там, де є багато конкретних фактів і ризик плутанини:
- e-commerce з цінами, наявністю, доставкою, поверненнями й варіантами товарів;
- локальний бізнес із кількома адресами або регіонами;
- медіа й блоги з авторством, датами, дослідженнями;
- SaaS із тарифами, FAQ, документацією, порівняннями;
- маркетплейси, каталоги, рейтинги, списки компаній;
- сторінки, які часто цитуються або мають потрапляти в AI-відповіді як джерела.
Якщо сайт має лише кілька простих лендингів без фактичної глибини, structured data теж варто впровадити. Просто не треба чекати від неї того, що має робити контент, PR і продуктова ясність.
Практичний чекліст
Перед тим як ставити задачу розробнику або SEO-команді, пройдіть цей список:
- Визначити головні типи сторінок: стаття, продукт, категорія, послуга, локальна сторінка, FAQ.
- Для кожного типу вибрати primary entity і відповідний Schema.org type.
- Описати єдину
Organizationз постійним@id, логотипом, URL і перевіренимиsameAs. - Додати
BreadcrumbListтам, де є ієрархія. - Для статей перевірити
headline,description,datePublished,dateModified,author,publisher,image. - Для товарів синхронізувати
price,availability, SKU/GTIN, shipping, returns і Merchant Center feed. - Для локальних сторінок звірити NAP-дані: name, address, phone.
- Перевірити, що всі поля є у видимому контенті або логічно підтверджуються сторінкою.
- Прогнати сторінки через валідатори й Search Console.
- Через 4-6 тижнів порівняти Search enhancements, AI-цитування, логи ботів і referral traffic.
Цей чекліст не гарантує AI-згадок. Він прибирає технічні причини, через які якісний контент може бути гірше зрозумілий.
Підсумок
Структуровані дані впливають на AI-видимість через ясність. Вони допомагають пошуковим системам і AI-шарам розуміти, що саме є на сторінці: компанія, автор, продукт, ціна, рейтинг, адреса, дата, джерело.
Але schema не працює окремо від решти системи. Потрібні доступний для краулерів сайт, сильний видимий контент, актуальні факти, внутрішні посилання, зовнішні згадки і нормальна аналітика. Формула проста: коректна розмітка + корисний текст + технічна доступність + узгоджені зовнішні дані дають кращі шанси на AI-видимість. Не гарантію, а саме шанс, який можна вимірювати й покращувати.


